Meet ConceptCore
Our core product ConceptCore is an end-to-end metadata solution tailored to publishers. It was built around our Auto-tagging engine and is used by news publishers around the world.
Dive into ConceptCore & Auto-tagging
You can use the buttons below to quickly jump to the section you are the most interested in.
What is metadata and why is it important?

Use cases to underline the importance of metadata

Topic pages and SEO boost
- Metadata can power Topic Pages and other strong internal linking structures.
- Topic Pages and internal linking is a fundamental aspect of boosting SEO performance.
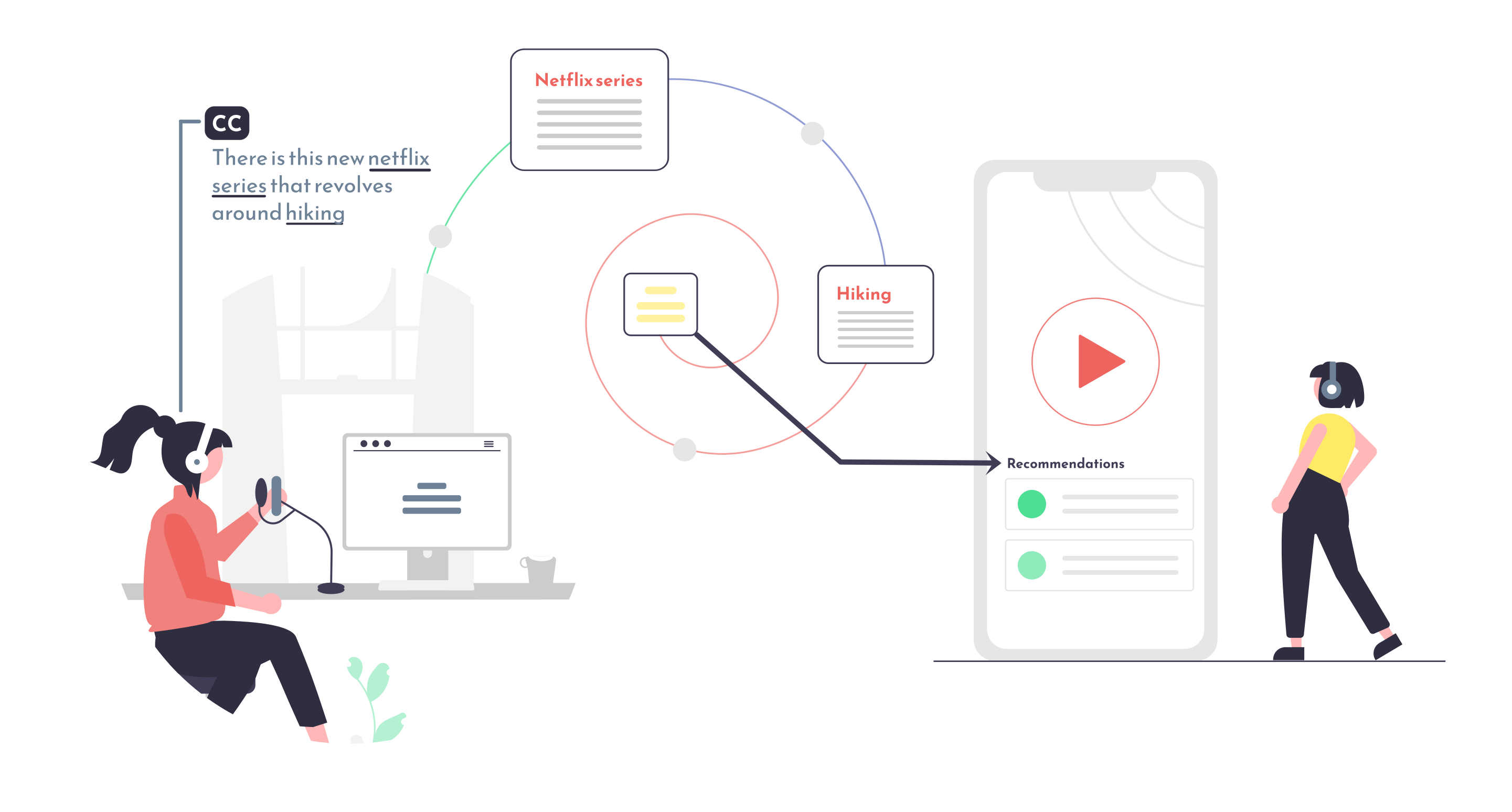
Personalization & Recommendations
- Metadata can be used to understand the interests of your users.
- User interests can be used to provide personal content recommendations.
- Metadata can also be used to allow your users to follow their interests and receive notifications of new content.
Site automation
- You can allow the metadata to control the initial placement of your content.
- Then you can aim your editors’ efforts towards fine-tuning the placement of breaking news.

Gain a deeper understanding of your content
- Find production inefficencies by comparing performance across verticals.
- Combine with user data and follow what your users are interested in.
- Use metadata as a basis for user segmentation.
Unify media types
- Match the metadata across multiple media types and allow for new use cases.
- For example Image Suggestions, match metadata from your article with metadata about your images to automatically suggest suitable images.
Index your digital archive
- If you have an archive with various content, it will be much more valuable with metadata.
- Metadata can be used to improve the navigation and easily enhance the search experience.
- In essence, it will make it possible to properly explore and reuse content of the past.

Why shouldn’t writers add metadata themselves?
What kind of metadata are we talking about?
Categories
Categories are high-level subjects with a specific purpose. This purpose could be to hold up the main site navigation or simplified content/production/interest analysis. Usually, we recommend 1 – 2 categories per article and that they should indicate the main aspect(s) of an article. The category part of the taxonomy usually isn’t changed very often.
Also, it is possible to integrate standards such as IPTC Media Topics or IAB Content Taxonomy as part of this.
Topics
Topics are more in-depth and detailed. Maybe you want to have a topic called Tea, for all your Tea interested users. Tea can then be activated as a followable tag and/or a Topic Page.
Generally topics can be used for detailed site navigation/automation, SEO including topic/theme pages, personalization functionality such as follow and get push notifications or personal news feeds and detailed user interest analysis.
Entities
Entities are named items of any of five subtypes. These subtypes are Person, Place, Organization, Event and Object. We usually have a natural understanding of Person, Place and Organization, but Event and Object may raise some questions. An Event is something that happens that is limited by time, such as the Summer Olympics 2016. An example Object could be a book or a movie. The use cases of entities are similar to that of topics.
P.S. We continuously update entities via our Wikidata Live Update service. You can also add your own or edit any of our suggested entities to suit your needs.
How do we get it into our system?
We are experienced with both building integrations and helping our customers/partners with theirs.
Currently there are available integrations to;
- Naviga - Writer
- Livingdocs
- WoodWing - Aurora
- Sourcefabric - Superdesk
- Norkon - Live Center
- WordPress
- Aptoma - DrPublish
If you are not using any of the systems above, we have the information you need to integrate our solutions yourself or with our help.

Why pick iMatrics?
Tailored For You
- We know each customer is unique – that's why we offer custom models build on your data.
- Flexibility is important. Either through your own input, or via industry standards, we help you customize the taxonomy to your needs.
- Via intuitive GUI tools, or API calls, you can control your data and easily tune the solution on your end.
Infinitely Scalable
- Updates are performed without any downtime.
- Our architecture is built to handle upscaling and downscaling seamlessly using proven tools on AWS.
Innovation Partner
- Our premium support will guide you on your journey.
- We are available for innovative projects to help you take your systems and sites to the next level.
- Become a part of iMatrics Metadata & Media Innovation hub, where we showcase the latest technology and use-cases.
- We arrange events to exchange experiences and find inspiration. This opens you up to our network of AI and metadata enthusiasts within the publishing space.
How does the Auto-tagging work?
The technical term for programs that analyze text is natural language processing, and there are thousands of engineers and researchers working in this field. That means there are fantastic resources to leverage. Our system uses a mix of state-of-the-art frameworks, traditional rule-based business intelligence, and our own proprietary AI methods. We combine these powerful methods with comprehensive databases based on open data such as OpenStreetMap and Wikidata to achieve the best result possible.
In short, we cherry-pick the best solutions to your specific problem.

Do you support any taxonomy standards?
On top of our own iMatrics News Taxonomy, we support IPTC Media Topics, IAB Content Taxonomy and use Wikidata IDs as a type of entity taxonomy. We also use OpenStreetMap for geodata. If you want us to add a new standard, just reach out!
What are the technical details?
ConceptCore consists of the following pieces;
- The Auto-tagging engine.
- The taxonomy database and our entity database, EntityDB.
- Wikidata Live Update, which is our live entity synchronization feature.
- Our administration suite, including the Concept Management tool, the Concept Suggestions inbox and the Tag Quality Assurance tool (aka Tagging Queue).
- CMS integrations.
- Education material.
There is also the Gender Balance Tool add-on with its Slack integration for feedback purposes.
Auto-tagging engine
The Auto-tagging engine lies at the center of the ConceptCore solution. It is built around our own proprietary, unsupervised and language independent classification algorithm. This algorithm in turn is based on our founder Berkant Savas' research in applied mathematics.
EntityDB
Our entity database which we commonly refer to as EntityDB is based on data from Wikidata, Wikipedia and OpenStreetMap. It is not just a collection of all the data from these three sources, but rather the results of an extensive ETL (Extract, Transform, and Load) process. We extract and combine the data, filter it extensively based on quality and overall usefulness to our customers, transform it into our data formats and load it into Elasticsearch/OpenSearch databases. Furthermore, this is not just a static script. We actively maintain and improve it based on customer needs, just like all our software.